
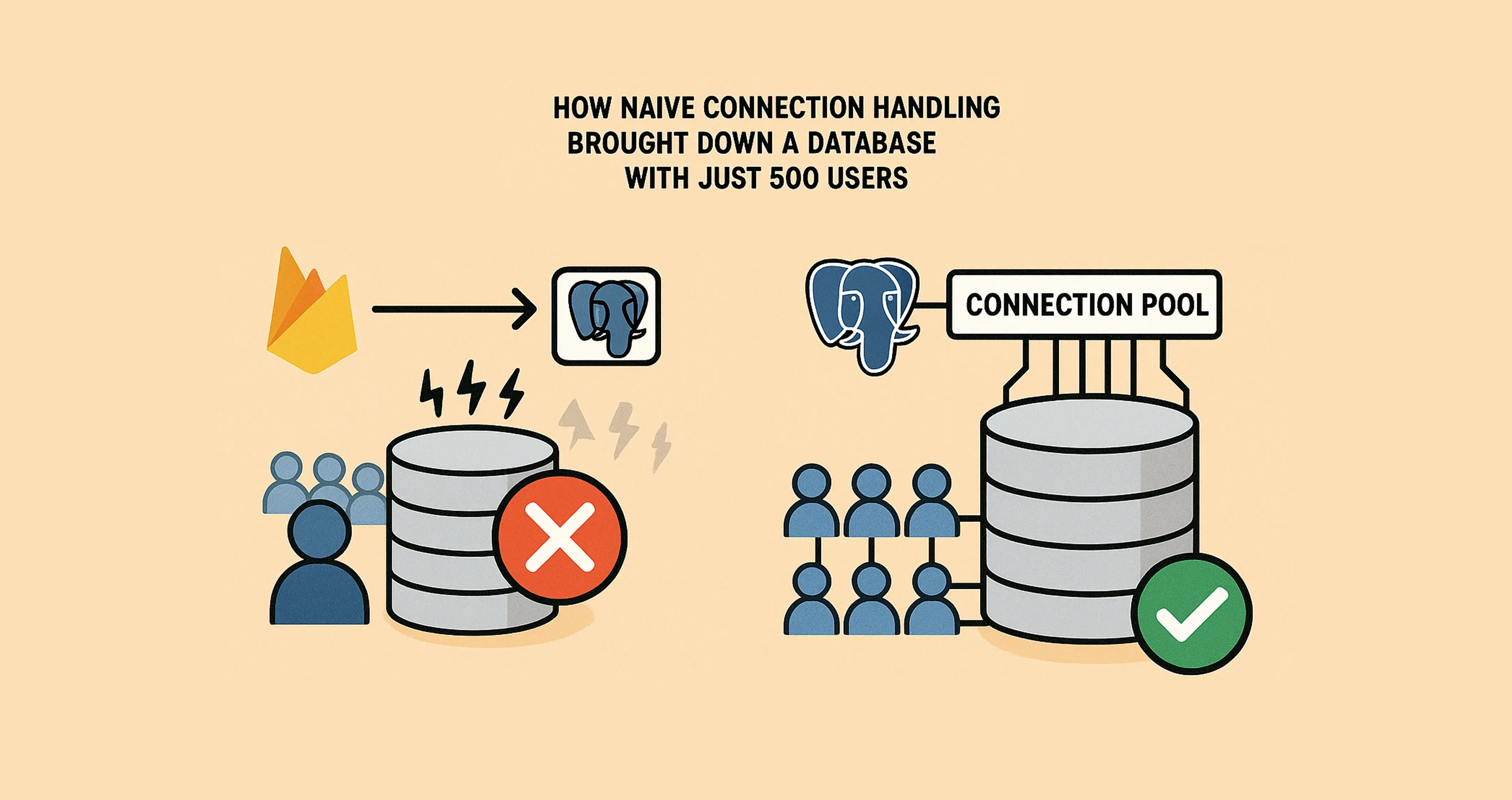
I’ve been building Evntt and recently moved its database from Firebase Firestore to PostgreSQL and settled on using the hosted option with Neon and then my database crashed. It was suddenly running out of connections when a small number of users started using the app. So what happened?
The way requests are handled in Evntt’s backend goes as follows:
- A request prepares a connection to the core platform database.
- The core platform database to fetch some details about which app (customer) this request belongs to.
- Make a connection to the app database.
This was mostly inherited from the Firebase days. The reason it worked was because Firebase allows you to re-use the app. When you called initializeApp you were forced to check if the app already initialized or not. Otherwise Firebase throws an exception.
In PostgreSQL land, you can just initialize unlimited amounts of clients and naively Evntt was configured so that each request created its own client for the platform database and its own client for the app (customer) database.
See the problem?
When a small load, say 500 users, started using the app, the database server was hammered with requests and soon enough it ran out of capacity to handle new requests. The aftermath is all requests starting failing. Other issues I was seeing as well was an increased memory pressure. For a small API it didn’t make sense that it needed at least 4GB of RAM to run.
Turns out that each PostgreSQL connection can take up to 1.3MB $^{1}$ and with so many connections no wonder I was running out of both connections and memory.
To fix this issue, there are 2 ways:
- Close each connection properly when a request finishes. (Seems obvious doesn’t it?)
- Use connection pooling and let the PostgreSQL client do its magic.
Given that each connection adds a chunky amount of memory and adds latency to each request, using connection pooling makes the most sense.
So in Node.js land, using postgres.js we have to setup a few things:
- Maximum number of connections: How many connections would the connection pool have as a maximum
- Idle time allowed for a connection: How long can the connection be idle for before terminating
- Maximum lifetime of a connection: How long can the connection live for
Each parameter has to be configured based on how the application is deployed and used so let’s dig into each one. I will use my setup as an example to guide how I calculated these values.
Let’s start by maximum number of connections. This value should be capped by how many max_client_conn your PostgreSQL server allows. It doesn’t make sense to set it at 100 if your server only supports 50. This leads us to how you deploy the application.
Evntt is deployed on Google Cloud Run and what it does is basically it spins instances of the API to handle requests based on some configuration parameters. In my setup, I specified that each instance can handle a max of 100 requests. So for example, if I get 200 requests then I get 2 instances. My max_client_conn was set at ~200 client connections as well based on the pricing plan I was on with Neon.
In this case, I had to adjust the maximum number of connections to ensure I never exceed the 200 limit set by Neon. My worst case scenario is that I consume all my limits on Google Cloud Run, that is 100 requests x 10 instances. Which means that each instance had to have a pool of 20 connections at most.
Idle time allowed is mostly influenced by usage patterns. In my case, the backend powers short-lived API requests which are mostly CRUD operations for a mobile app. That means a short time window say 20 seconds is more than enough to ensure that the connection is no longer needed. You might also want to consider how periodic you are getting requests. Remember that the aim is to avoid constant ending then re-establishing connections.
Maximum lifetime is also influenced by usage patterns. You want to set it to a value that avoids re-creating connections but you also don’t want too many open connections which ends up consuming resources on your database server, and in my case costing more money as I was using a database as a service offering. Usually sensible values are within 30 minutes to 2 hours. If no one is making requests within this timeframe then you might as well terminate any connection to your database until the next usage and save some resources (and money).
After implementing connection pooling with the calculated parameters, the results were immediate and dramatic. Request throughput improved significantly, request times decreased, and everything was back to normal. The memory usage dropped from over 4GB to a reasonable level, and the database connection limit issues completely disappeared.
This experience taught me a valuable lesson about the differences between Firebase and PostgreSQL connection models. While Firebase’s enforced app reuse prevented connection proliferation, PostgreSQL’s flexibility requires more careful resource management. Connection pooling isn’t just an optimization—it’s essential for any production application that expects real user load.
The key takeaway is that when migrating from one database technology to another, it’s crucial to understand not just the API differences, but also the underlying resource management models. What works in one system might be catastrophic in another, and proper load testing with realistic user volumes is essential before going live.
This blog was written by me and edited by Claude AI.